
Architecture & Design
Zero Downtime Since Deployment — Enterprise Infrastructure for a Leading NYC Architecture Firm
A ground-up, zero-compromise infrastructure built with redundancy as a first-order constraint — network, compute, storage, wireless, and access control, with no single point of failure tolerated anywhere in the stack.
The Challenge
Legacy infrastructure built for a smaller firm
When a premier New York City architecture firm scaled past 100 employees and relocated to a new headquarters, their legacy bare-metal Windows Server environment could no longer support the high-concurrency, high-throughput demands of their design workflow. Staff worked directly off shared storage rather than copying files locally — a workflow pattern that ruthlessly exposes any latency or bandwidth weakness in the underlying infrastructure. Large-format CAD and BIM assets, real-time multi-user collaboration, and uninterrupted application availability were non-negotiable requirements.
RSystems was engaged to architect a ground-up, zero-compromise infrastructure covering wired networking, wireless, compute, storage, and access control. Redundancy was a first-order design constraint at every layer: redundant power, controllers, chassis, and paths throughout. The goal wasn't incremental improvement — it was an environment that could absorb any single component failure without interruption.
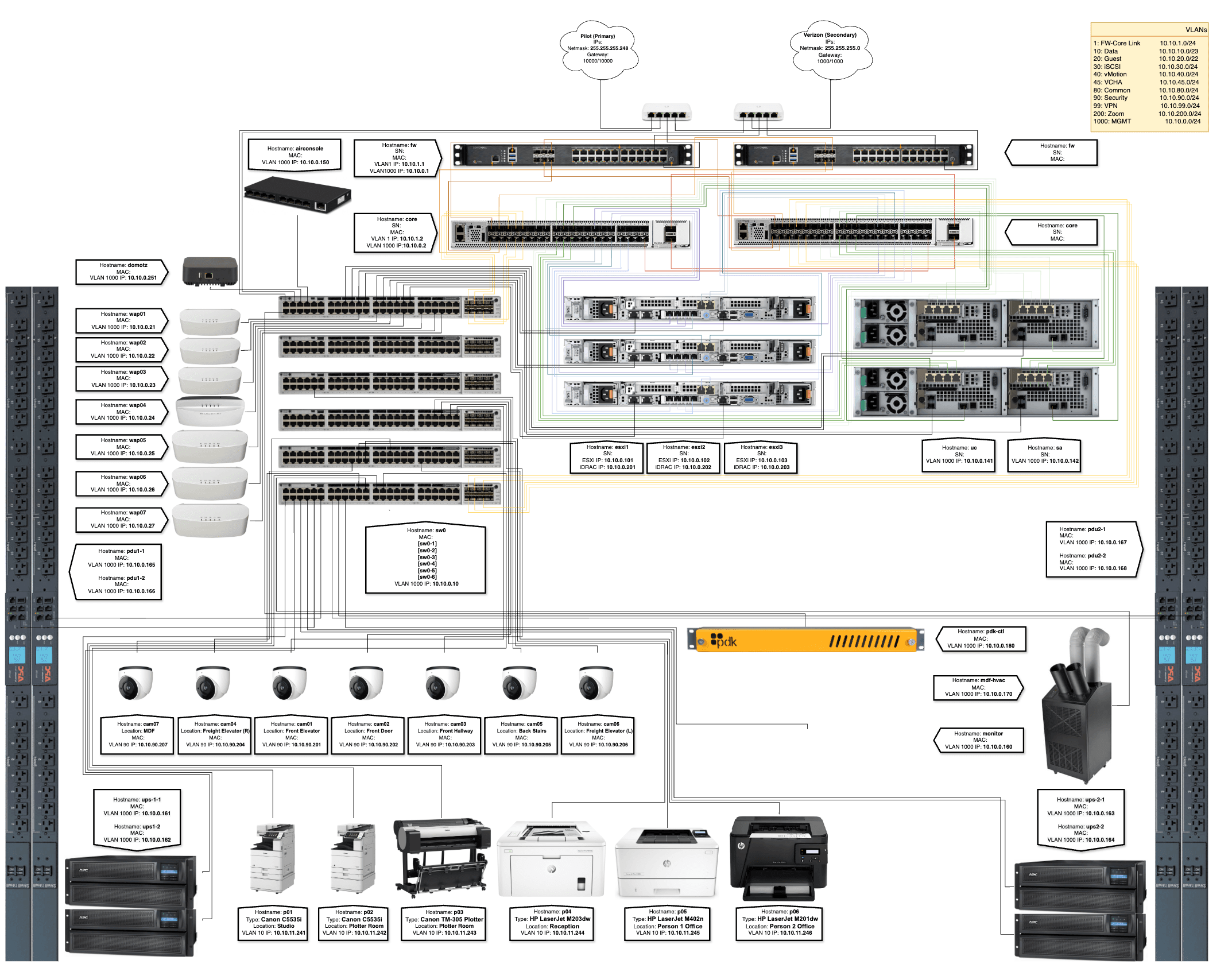
Network Architecture
A fully redundant switching fabric
Access Layer
Six Cisco Catalyst 9300 switches form the access layer as a single logical stack, providing nearly 300 ports across the office floor. The top stack member — a multi-gigabit variant — is dedicated exclusively to wireless access point uplinks, supporting 5 Gbps per AP uplink with headroom for future 10 Gbps capacity. The stack was specified with 8-port 10GbE expansion modules to provide significant uplink headroom beyond what the licensing tier requires.
Beyond data-plane stacking (each inter-switch link operates at 480 Gbps, dual cables per switch providing 960 Gbps of intra-stack capacity), Cisco StackPower connects the power supplies of all stacked switches into a single logical power domain. A switch member remains fully operational even if both of its local PSUs fail simultaneously, provided the aggregate pool has sufficient capacity from neighboring members. Every switch carries dual PSUs on independent 30-amp UPS circuits — defense-in-depth at the power layer.
Core Layer
Dual Cisco Catalyst 9500 switches operate via StackWise Virtual — a unified control plane in which both chassis are simultaneously active and authoritative. Neither chassis can enter a split-brain state. From the perspective of any connected device, the two physical switches are a single logical entity.
This enables true cross-chassis EtherChannel: all 12 access-to-core uplinks function as a single bundle, providing 120 Gbps of aggregate bandwidth between layers with simultaneous throughput and link-level redundancy — and no spanning tree blocking. Both core switches carry redundant PSUs on independent circuits.
Firewall & WAN
A SonicWall NSA 4700 pair operates in active/passive HA, selected specifically for its ability to sustain full deep-packet inspection at 10 Gbps line rate. The site runs a 10 Gbps primary WAN circuit with a 1 Gbps backup — the 4700 was sized to ensure the firewall is never the throughput ceiling at either circuit speed. Downstream connectivity from each firewall to the core uses four bonded 10GbE links (40 Gbps per firewall). Failover is automatic and stateful, typically converging within 2–3 seconds. Both units carry redundant power on independent circuits.
Thermal Management
The server room presented a challenge common in built-out office environments: extending dedicated precision cooling would have required tens of thousands of dollars in additional ductwork and chiller capacity — not viable given the space geometry. RSystems specified and installed a dedicated HVAC unit within the server room with a hot-aisle/cold-aisle design: cold supply air directed at rack front faces, hot exhaust captured and ducted into an adjacent room. Stable operating temperatures have been maintained since deployment.
Wireless
Enterprise Wi-Fi 6 in a hostile RF environment
The firm's open floor plan — glass partitions, reflective surfaces, dense client populations in continuous motion — presents a genuinely hostile RF environment. RSystems over-specified radio capacity relative to theoretical client density so that practical performance remained top-tier even as conditions diverged from lab ideals.
A tiered Ruckus Wi-Fi 6 deployment was specified by per-zone density:
- Ruckus R850 (8×8:8 MU-MIMO) in high-density open-plan design zones and primary desk clusters — the 8-stream radio capacity is critical for managing co-channel interference where many clients are simultaneously active in a small area
- Ruckus R650 / R610 in conference rooms and corridor coverage zones
All APs were cabled with dual Cat6a cables supporting 10GbE, ensuring neither cabling nor hardware becomes a bottleneck on a 5–10 year refresh cycle.
Rather than purchasing physical SmartZone controller appliances (~$10,000 per unit at time of deployment), RSystems virtualized redundant SmartZone instances as VMs on the Dell/VMware cluster — eliminating $20,000 in dedicated controller hardware without sacrificing any management or roaming capability. VM-level HA and vMotion portability are added benefits.
The controller-managed roaming model is central to wireless performance in this environment. Without a controller, roaming decisions are left to client devices — leading to the sticky client problem, where a laptop holds a degraded AP signal rather than handing off to a stronger one. SmartZone continuously monitors per-client RSSI and SNR across the AP fabric and issues directed disassociations, seamlessly transitioning clients to the optimal AP during active video calls or large file transfers. This orchestration is invisible to the user.
Storage
Dual-controller SAN with 80 Gbps aggregate bandwidth
Primary SAN — Synology UC3200
Selected specifically for its dual active-active iSCSI controllers. Each controller has its own processor, RAM, and dedicated network interfaces. Path failover on controller failure occurs at the hardware level with nanosecond-range latency — no controller election, no convergence delay, no VM I/O timeout. Both controllers serve I/O continuously.
Disk configuration: 8 × 16TB SAS HDD with 4 × 1.92TB SAS SSD read/write cache tier. The cache tier handles small-block, high-IOPS workloads; spinning disk handles large sequential transfers. The tiering engine dynamically promotes and demotes data based on access patterns.
iSCSI connectivity: 8 discrete 10GbE interfaces, each with a unique IP address, all running Jumbo Frames (MTU 9000) — 80 Gbps of raw iSCSI bandwidth. Each ESXi host uses 3 dedicated 10GbE NICs for iSCSI, providing 9 host-side paths in aggregate, closely matched to the 8 appliance-side paths. The network fabric was deliberately over-provisioned relative to the storage appliance's maximum sustainable I/O throughput — the disk array is the ceiling, not the network. That is by design.
Three precision tuning optimizations were applied: ALUA MPIO for intelligent path selection that avoids unnecessary inter-controller traffic; Round-Robin IOPS threshold reduced from 1,000 to 1 (distributing I/O across all 8 active paths simultaneously rather than allowing a single path to carry disproportionate load); and EtherChannel hashing algorithms coordinated across Cisco switch and VMware vSwitch layers to ensure balanced traffic distribution across all physical links.
Secondary SAN — Synology SA3200D
Active/passive dual-controller unit serving as backup target and extended services platform. The SA3200D was chosen over a second UC3200 for its support of native cloud replication to AWS S3, DNS services, and additional data management capabilities required by the firm's workflow. The trade-off — a few seconds of failover latency versus nanoseconds on the primary — is acceptable on the backup tier where brief interruptions are tolerable.
Compute
VMware cluster on Dell PowerEdge
Three Dell PowerEdge R650 servers form the compute cluster, each configured with 128GB RAM (half-filled slots reserved for future expansion) and 6 × 10GbE SFP+ NICs: 3 dedicated to iSCSI storage traffic, 3 bonded via EtherChannel for VM data traffic, vMotion, and management.
The cluster runs VMware ESXi 7 under Essentials Plus licensing — a one-time perpetual purchase of approximately $7,000 covering up to three hosts. This licensing tier includes vMotion and DRS, both central to the cluster's operational model.
vMotion enables live migration of running VMs between hosts with zero downtime — firmware updates, hardware replacements, and maintenance can be performed during business hours by migrating workloads off the target host first.
DRS monitors real-time CPU and RAM utilization and automatically rebalances workloads across hosts. The cluster is sized to sustain full workload capacity with any single host offline.
Anti-affinity rules prevent redundant service pairs from co-locating on the same host. Without them, DRS might place both domain controllers on the same physical chassis — defeating the redundancy entirely. Anti-affinity rules are defined for all critical service pairs, including domain controllers and the SmartZone controller pair.
The cluster supports Active Directory, file sharing, wireless controllers, cloud sync agents, a Network Video Recorder for the office camera system, print servers, and additional line-of-business VMs. All VM storage is centralized on the shared SAN — replicated and backed up, not siloed on individual host disks.
For context: hyperconverged platforms capable of meeting these throughput and redundancy requirements would have carried a price tag exceeding $100,000 per node.

Access Control
Cloud-managed access control, provisioned through Entra
RSystems deployed PDK as the firm's physical access control platform, integrated directly with Microsoft Entra ID (Azure AD) as the identity source of truth.
The integration eliminates a manual provisioning step that is easy to miss and costly to overlook. When a new employee is added to Entra, PDK automatically creates their access control profile and sends them an invite to enroll their smartphone as a credential. No fob to issue, no IT ticket to file, no separate admin console to manage.
Staff use their phones at door readers via NFC and Bluetooth Low Energy — a faster and more reliable experience than physical credentials, and one that scales gracefully as the organization grows. Offboarding is equally automatic: removing a user from Entra revokes their building access without any additional action.
Outcomes
What we delivered.
- Zero infrastructure downtime since deployment
- 5–7 Gbps real-world internal file transfer throughput — on par with local NVMe, delivered over shared SAN
- 10 Gbps primary WAN with 1 Gbps backup — SonicWall NSA 4700 HA pair sustains full DPI at 10 Gbps line rate
- All 12 access-to-core uplinks active simultaneously — no spanning tree blocking
- 80 Gbps aggregate iSCSI bandwidth from primary SAN to VMware cluster
- SmartZone virtualization eliminated $20,000 in dedicated controller hardware
- Full VMware cluster deployed under $7,000 in licensing costs
- PDK access control provisioned automatically through Entra — phones as credentials, zero manual issuance
Engineer Resilience
Can your office survive a failed drive, switch, or firewall without going dark?
We design networks and infrastructure with redundancy built in, so a single failure never stops the work. Let's review where your single points of failure are.
Let's TalkRelated
To design the same kind of fault-tolerant infrastructure for your office, these services are the place to begin:
For the concepts behind a redundant design, see our University guides on virtualization, networking, and firewalls:
More infrastructure built to stay standing: